1. 事件简述
有一台服务器,发现长时间系统负载很高,且系统负载没能降下来,使用top进行查看
top - 14:46:15 up 481 days, 18:18, 1 user, load average: 61.45, 58.41, 45.99查看这台服务器进程,该台服务器搭建了oracle,发现有较多运行进程是数据库的,因是测试数据库,所以重启数据库打算释放运行进程,但重启过程中,发现数据库启不起来,处于unhealthy状态,且反应很慢,遂查看磁盘IO使用情况,使用iostat -x 2进行查看:

发现磁盘sdb以及逻辑卷dm-2磁盘I/O利用率已经100%,已经爆满。
2. 问题分析
从截图可以看到关键性能指标如下:
2.1 CPU总体状态(avg-cpu)
| 指标 | 数值 | 含义 |
|---|---|---|
| %user | 1.64% | 用户态 CPU 占用低 |
| %system | 0.75% | 统态 CPU 占用低 |
| %iowait | 46.92% | ⚠️ 非常高,表示大量 CPU 在等待磁盘 I/O 完成 |
| %idle | 50.69% | CPU 有空闲,但被 I/O 阻塞严重 |
说明:CPU 并不是瓶颈,但几乎一半的 CPU 时间都在等待磁盘 I/O。
2.2 磁盘I/O性能
从设备行可以看到:
| 设备 | r/s | w/s | await(ms) | svctm(ms) | %util | 说明 |
|---|---|---|---|---|---|---|
| sdb | 49 | 14 | 49.76 | 15.87 | 100% | 已打满,读写都有,I/O 队列严重 |
| dm-2 | 66 | 10 | 41.30 | 13.16 | 100% | 逻辑卷,同样被打满 |
| 其他设备 | 0 | 0 | 0 | 0 | 0 | 空闲 |
可以看出:
sdb与dm-2(逻辑卷)磁盘I/O已100%利用率;await在40~50ms,属于非常高的延迟;- 系统load average超高(61+),主要由I/O阻塞县城导致。
2.3 系统负载(top)
load average: 61.45, 58.41, 45.99
系统负载远高于 CPU 核心数,说明:
- 大量进程在等待I/O;
- 并非CPU计算问题,而是磁盘瓶颈导致任务排队。
2.4 分析总结
单块磁盘(sdb)和逻辑卷(dm-2)被过度使用
- 可能是数据库、日志或缓存目录集中在同一磁盘;
- 或NFS、虚拟机镜像等I/O密集型任务过载。
I/O调度延迟高
await接近50ms,说明I/O队列严重积压;avgpu-sz≈12,表示平均队列长度过长。
可能的文件系统碎片或不合理挂载
- 如果是ext4/xfs长时间运行未优化,碎片和日志写入可能造成延迟。
底层资源池资源紧张
- 因该台服务器是虚拟机,具体资源来源于底层资源池,有可能底层资源池被其他虚拟机过度使用,挤占了该台服务器的资源。
3. 解决问题
根据以上分析,进行逐一排查,最终找到问题根源:底层资源池I/O被某台虚拟机占用了75%以上,导致底层I/O在分配给其他虚拟机时不够用了,通过释放某台虚拟机正在使用的服务资源,从而释放出占用的I/O,磁盘I/O释放出来后,该台服务器恢复正常,如下:
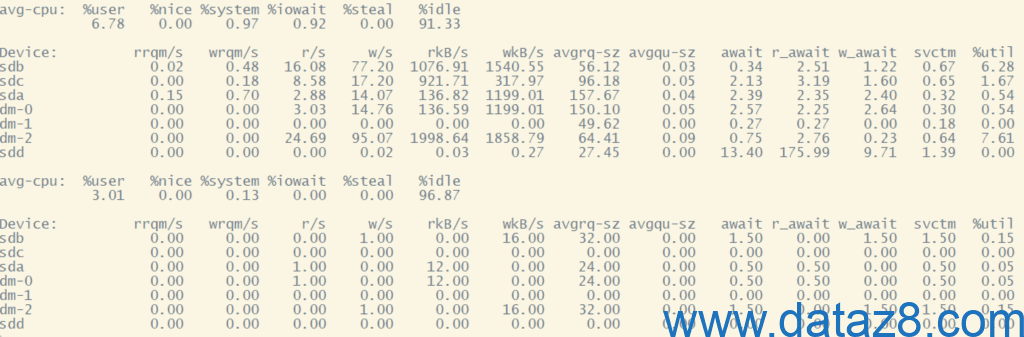
4. 参数含义
4.1 iostat输出
4.1.1 avg-cpu该行输出含义
这是系统性能监控中最重要的一行之一,如截图中部分:
avg-cpu: %user %nice %system %iowait %steal %idle
1.64 0.00 0.75 46.92 0.00 50.69这一行通常来自 iostat(或 sar -u)输出,显示的是 CPU 各种使用状态的平均分布。
字段含义总览
| 字段 | 含义 | 说明 |
|---|---|---|
| %user | 用户态CPU占用率 | 执行用户进程(非内核)时消耗的CPU比例 |
| %nice | 调整优先级后的用户态CPU占用率 | 执行被“nice”调整过优先级的进程所占用的CPU |
| %system | 内核CPU占用率 | 操作系统内核执行任务(如系统调用、驱动、IO调度)占用的CPU比例 |
| %iowait | 等待I/O完成的CPU时间比例 | CPU处于等待磁盘/网络I/O响应的状态 |
| %steal | 虚拟化“被盗用”CPU时间 | 虚拟机中,宿主机分配给其他虚机的CPU时间(虚拟机几乎为0) |
| %idle | 空闲CPU时间比例 | CPU无任务执行、完全空闲的时间百分比 |
原理说明(CPU状态来源)
系统内核统计每个CPU在不同状态下的累计时间,主要有:
- user:用户代码执行;
- system:内核代码执行;
- iowait:CPU空闲但有I/O等待;
- idle:CPU真正空闲;
- nice:带优先级调整的用户任务;
- steal:虚拟化被抢占的CPU时间。
iostat 或 sar 会在一段时间采样后输出每种状态的占比。
截图中的实际数值分析
| 指标 | 数值 |
|---|---|
| %user = 1.64% | 用户态负载极低,说明应用计算压力不大 |
| %system = 0.75% | 系统调用、内核操作很少 |
| %iowait = 46.92% ⚠️ | 非常高! 表示CPU近一半时间都在等待磁盘I/O完成 |
| %idle = 50.69% | 一半时间CPU真正空闲,但因为I/O等待,无法充分利用 |
| %nice = 0.00% | 使用 nice 调整的进程 |
| %steal = 0.00% | 虚拟机 CPU 得到了完全调度,没有被宿主机抢走时间 |
关键指标解释重点
1) %user + %system
代表 CPU 真正“干活”的时间比例(执行应用 + 内核)。
- 正常服务器负载:10% ~ 70%;
- 如果接近 100%,CPU是瓶颈;
- 这里只有 2.39%,CPU 很闲。
2) %iowait
表示CPU空闲但被I/O阻塞。
- 正常:0~5%;
- 中等:5~15%;
- 超高:>20%(严重I/O瓶颈);
- 这里是 46.92% → 极高!
说明:
CPU大部分时间在等磁盘响应(例如数据库读写、日志写入、NFS、虚拟磁盘延迟等)。
3)%idle
CPU真正空闲的比例。
- 如果
%idle很低 (<10%) 且%user/%system高 → CPU计算压力大; - 如果
%idle高但%iowait也高 → CPU本身闲着,但被I/O拖慢; - 这里情况:
idle 50.69% + iowait 46.92%典型的 I/O瓶颈导致CPU空等。
4) %steal
如果是虚拟机上运行(如 KVM、VMware),该值 >0 表示宿主机CPU资源被其他虚机抢占。
- 实机通常为 0;
- 若 >10%,说明虚拟化层竞争严重;
- 这里是 0 → 无虚拟化问题。
如何快速判断瓶颈类型
| 场景 | 典型特征 | 结论 |
|---|---|---|
%user 高 | 应用计算密集型 | CPU瓶颈 |
%system 高 | 内核调度或系统调用频繁 | 可能是网络/内核调用瓶颈 |
%iowait 高 | CPU空等磁盘I/O | 磁盘或存储瓶颈 |
%idle 高但系统慢 | 大量I/O等待 | I/O延迟高导致应用响应慢 |
%steal 高 | 虚拟化CPU竞争 | 宿主机资源不足 |
命令补充
# 1. 实时查看CPU各状态分布
mpstat 1
# 2. 查看具体进程的I/O等待情况
pidstat -d 1
# 3. 查看谁导致高 iowait
iotop -aoP4.1.2 Device该行输出含义
Device 这一行是 iostat -x 命令(或类似工具如 sar -d)输出的核心部分,用来展示各个磁盘或逻辑卷的详细 I/O 性能指标
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util字段详解
| 字段 | 含义 | 解释说明 | 关键判断 |
|---|---|---|---|
| Device | 设备名称 | 如 sda, sdb, dm-0(逻辑卷)等 | 用于区分不同物理/逻辑设备 |
| rrqm/s | 每秒合并的读请求数 | 当多个相邻的读请求被内核合并为一个时计数 | 高值表示读请求较集中 |
| wrqm/s | 每秒合并的写请求数 | 同上,用于写操作 | 高值表示写请求较集中 |
| r/s | 每秒发送到设备的读请求数 | 每秒磁盘读 I/O 次数(IOPS) | 越高说明读负载重 |
| w/s | 每秒发送到设备的写请求数 | 每秒磁盘写 I/O 次数 | 越高说明写负载重 |
| rkB/s | 每秒读出的数据量(KB) | 表示读吞吐量 | 反映读速率(KB/s) |
| wkB/s | 每秒写入的数据量(KB) | 表示写吞吐量 | 反映写速率(KB/s) |
| avgrq-sz | 平均每个I/O请求的大小(扇区数或KB) | 请求越大,表示顺序I/O;越小表示随机I/O | 小值=随机I/O,多为数据库类型负载 |
| avgqu-sz | 平均请求队列长度 | 表示磁盘上等待处理的I/O请求数 | >1 表示I/O排队严重 |
| await | 每个I/O平均等待时间(ms) | 包括排队时间 + 服务时间 | >20ms 说明磁盘延迟明显 |
| r_await | 读请求平均等待时间(ms) | 单独的读请求响应延迟 | 对读操作分析有用 |
| w_await | 写请求平均等待时间(ms) | 单独的写请求响应延迟 | 对写操作分析有用 |
| svctm | 平均服务时间(ms) | 每个I/O完成所需时间,不含排队 | ≈ await 表示队列不长;远小于 await 表示排队严重 |
| %util | 设备利用率 | 表示该设备每秒中有多少时间在忙 | 接近100%说明磁盘已满载 |
举例说明
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdb 6.00 0.00 49 14 2208 80.00 72.63 11.95 49.76 48.59 53.86 15.87 100.00
分析:
| 指标 | 值 |
|---|---|
| r/s=49, w/s=14 | 每秒读49次,写14次 |
| rkB/s=2208 | 每秒读2.2MB数据 |
| wkB/s=80 | 每秒写80KB数据(读远多于写) |
| avgrq-sz=72.63 | 每次I/O请求约72KB(中等偏小,略随机) |
| avgqu-sz=11.95 | 平均有12个请求在排队(非常高) |
| await=49.76ms | 平均每个I/O需等待约50ms(很慢) |
| svctm=15.87ms | 真正服务时间约15ms,说明还有约35ms在排队 |
| %util=100% | 磁盘100%忙碌,瓶颈明显 |
关键指标判断
| 指标 | 正常范围 | 异常判断 |
|---|---|---|
%util | < 70% | ≥90% → 磁盘过载 |
await | < 10ms(SSD)< 30ms(HDD) | > 50ms → 严重延迟 |
avgqu-sz | < 1 | > 2 → 有明显排队 |
avgrq-sz | 128KB+ → 顺序I/O | < 64KB → 随机I/O,多线程数据库或虚拟化负载 |
辅助理解关系图
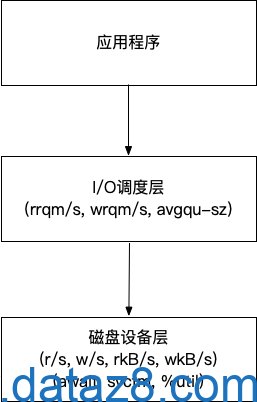
小结
| 分类 | 字段 | 说明 |
|---|---|---|
| 请求速率 | r/s, w/s | 每秒读写次数 |
| 吞吐量 | rkB/s, wkB/s | 每秒传输数据量 |
| 请求特性 | avgrq-sz | 每次I/O大小(顺序 or 随机) |
| 排队情况 | avgqu-sz | 平均等待队列长度 |
| 延迟 | await, r_await, w_await | 平均I/O响应时间 |
| 设备忙碌度 | %util | 磁盘使用率(接近100%表示瓶颈) |
4.2 top输出
top 命令的第一行(系统总体状态)是系统性能分析中最核心的一行 :
top - 14:46:15 up 481 days, 18:18, 1 user, load average: 61.45, 58.41, 45.99格式说明
top第一行的典型格式为:
top - <时间> up <运行时长>, <登录用户数> users, load average: <1分钟>, <5分钟>, <15分钟>字段详解
| 字段 | 示例值 | 含义 |
|---|---|---|
| top – 14:46:15 | 当前系统时间 | 表示 top 输出时的系统本地时间 |
| up 481 days, 18:18 | 系统已运行481天18小时18分 | 表示系统自上次重启以来的持续运行时间(uptime) |
| 1 user | 当前登录系统的用户数 | 一般包括终端或SSH登录的会话数 |
| load average: 61.45, 58.41, 45.99 | 系统负载均值 | 分别表示过去 1分钟、5分钟、15分钟 的平均负载 |
重点:load average含义详解
这是最关键的部分之一。
1)含义
load average 表示 处于“可运行”或“不可中断(D状态)”状态的进程平均数。 简单来说:
- 它反映了系统任务队列的拥堵程度;
- 包括正在运行的任务 + 正在等待 CPU 或 I/O 的任务。
⚠️ 注意:它不是 CPU 使用率,而是“排队长度”。
2)判断标准(与CPU核心数相关)
| CPU核心数 | 合理负载上限 | 说明 |
|---|---|---|
| 1核 | ≈1.0 | 表示刚好满负荷运行 |
| 4核 | ≈4.0 | 超过4表示排队了 |
| 8核 | ≈8.0 | 超过8表示系统繁忙 |
| 32核 | ≈32.0 | 超过32说明存在I/O等待或线程拥堵 |
因此要结合CPU核心数进行分析。
3)该截图上情况:
load average: 61.45, 58.41, 45.99这表示:
- 过去1分钟平均有 61.45个任务 同时在运行或等待;
- 过去5分钟约58;
- 过去15分钟约46。
结论:系统长时间处于严重过载状态 — 即大量任务在等待资源(CPU或I/O)。 结合前面发的 iostat 截图:
%iowait高达 46.9%,磁盘sdb利用率 100%。
所以此时的高 load average 是由 磁盘 I/O 堵塞 引起的,而非 CPU 饱和。
整体解释总结
| 字段 | 含义 | 当前情况 |
|---|---|---|
时间 (14:46:15) | 当前系统时间 | 正常 |
up (481 days, 18:18) | 系统运行时长 | 系统非常稳定(近1.5年未重启) |
user (1 user) | 登录用户数 | 正常 |
load average (61.45, 58.41, 45.99) | 系统负载平均值 | ⚠️ 极高,系统阻塞严重 |
延伸分析:load高的原因分类
| 原因类型 | 典型表现 | 验证命令 |
|---|---|---|
| CPU过载 | %us 和 %sy 高 | top、mpstat |
| I/O等待过多 | %wa 高,iostat %util≈100% | iostat -x 1 |
| 内存不足 | 大量swap,load缓慢上升 | vmstat 1 |
| 僵尸或阻塞线程 | 进程D状态(不可中断)多 | ps -eo pid,ppid,stat,cmd |grep ' Z' |